
注意:
在创建 KVM 虚拟机之前要先安装 KVM 并创建 KVM 虚拟网络
软件准备:
在 Rocky Linux 官网上下载安装系统所需要的镜像:
https://rockylinux.org/download
正文:
步骤目录:
步骤一:理解创建 KVM 虚拟机模板的目的
步骤二:为这个虚拟机创建硬盘文件
2.1 创建硬盘文件
2.2 确认硬盘文件已创建
步骤三:使用 KVM 和刚刚创建的硬盘文件新安装一台虚拟机
3.1 启动 KVM 的 virt-manager
3.2 在 virt-manager 上的左上角点击文件之后点击 “新建虚拟机”
3.2.1 选择以本地安装介质的方式安装系统
3.2.2 选择安装系统的系统镜像
3.2.3 设置内存大小和 CPU 核心数
3.2.4 选择用刚刚创建的硬盘文件来安装系统
3.2.5 给虚拟机命名并选择虚拟网络
3.2.6 开始安装系统
3.2.7 选择系统语言
3.2.8 之后进行系统配置界面
3.2.8.1 通过 “INSTALLATION DESTINATION” 对硬盘进行分区
3.2.8.2 取消 “KDUMP”
3.2.8.3 选择最小化安装系统
3.2.8.4 设置 root 密码
3.2.9 之后点击右下角的 “Begin installation”
3.2.10 安装完成后重启
3.2.11 在安装系统的过程中需要注意的内容总结
步骤四:进入新创建虚拟机修改配置
4.1 修改网卡个性化设置
4.1.1 修改网卡配置文件
4.1.2 使修改的网卡配置生效
4.2 禁用 SELinux
4.3 禁用空路由
4.4 添加 Console 配置
4.4.1 修改 grub 内核配置文件
4.4.2 使修改的 grub 内核配置生效
4.5 将系统自动挂载的硬盘从使用 UUID 换成硬件路径
4.5.1 显示根分区的 UUID
4.5.2 在自动挂载文件里将根分区的 UUID 换成硬件路径
4.6 删除不用的程序
4.7 对虚拟系统进行升级
4.8 进行分区扩展
4.8.1 安装分区扩展软件
4.8.2 给开机自启配置文件相应的权限
4.8.3 设置开机自动扩容根目录
4.9 修改虚拟机系统的名称
4.10 启用 serial 服务实现通过 virsh console 命令控制虚拟机
4.11 清除虚拟系统的历史命令
4.12 关闭虚拟机
步骤五:在真机上对虚拟机进行清理优化
步骤六:此时就可以将此虚拟机的硬件文件作为模板进行批量克隆虚拟机了
具体的操作步骤:
步骤一:理解创建 KVM 虚拟机模板的目的
主要用于批量克隆出新的 KVM 机器,节约创建新虚拟机的时间
步骤二:为这个虚拟机创建硬盘文件
2.1 创建硬盘文件
(只在真机上执行以下步骤)
# qemu-img create -f qcow2 /var/lib/libvirt/images/rockylinux8.qcow2 10G(补充:这里以创建 10G 大小的 rockylinux8.qcow2 硬盘文件为例)
2.2 确认硬盘文件已创建
(只在真机上执行以下步骤)
# ls /var/lib/libvirt/images/ | grep rockylinux8.qcow2(补充:这里以显示 rockylinux8.qcow2 硬盘文件为例)
步骤三:使用 KVM 和刚刚创建的硬盘文件新安装一台虚拟机
3.1 启动 KVM 的 virt-manager
(只在真机上执行以下步骤)
# virt-manager3.2 在 virt-manager 上的左上角点击文件之后点击 “新建虚拟机”
(只在真机上执行以下步骤)
(步骤略)
3.2.1 选择以本地安装介质的方式安装系统
(只在真机上执行以下步骤)
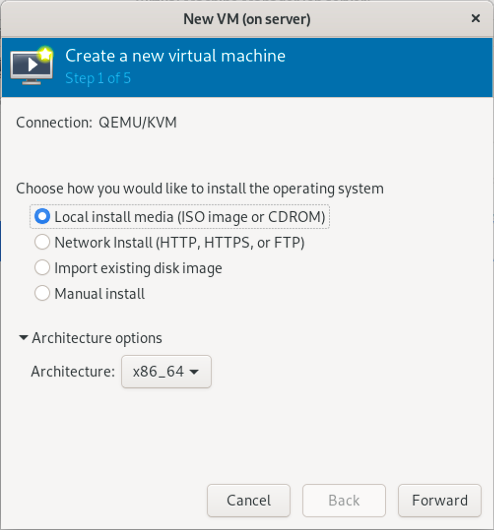
3.2.2 选择安装系统的系统镜像
(只在真机上执行以下步骤)
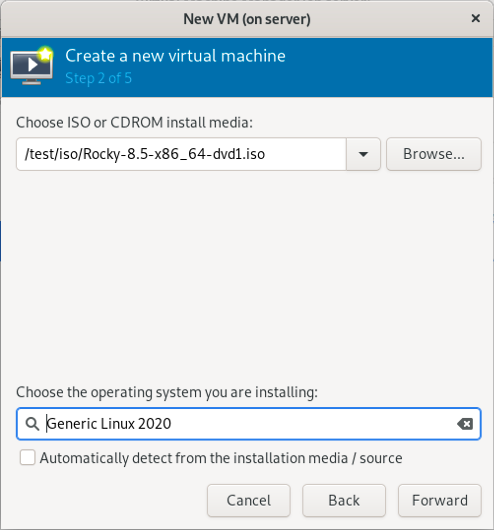
(补充:这里以使用 Rocky-8.5-x86_6-dvd1.iso 系统镜像为例)
3.2.3 设置内存大小和 CPU 核心数
(只在真机上执行以下步骤)
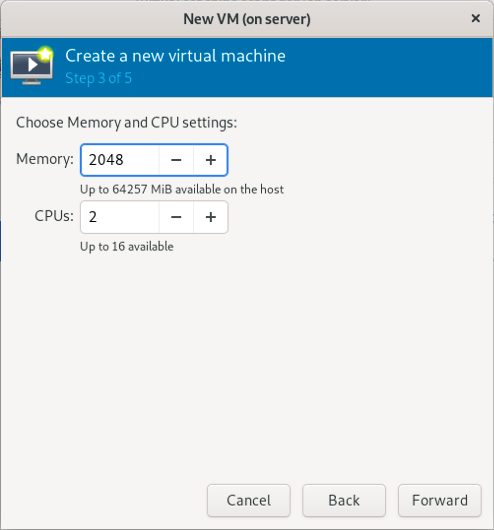
(补充:这里以设置 2048 MiB 内容和 2 核 CPU 为例)
3.2.4 选择用刚刚创建的硬盘文件来安装系统
(只在真机上执行以下步骤)
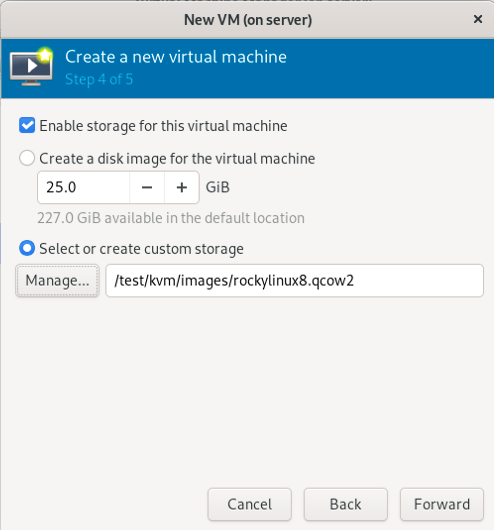
(补充:这里以使用 rockylinux8.qcow2 硬盘文件为例)
3.2.5 给虚拟机命名并选择虚拟网络
(只在真机上执行以下步骤)
(注意:虚拟网络必须提前创建好)
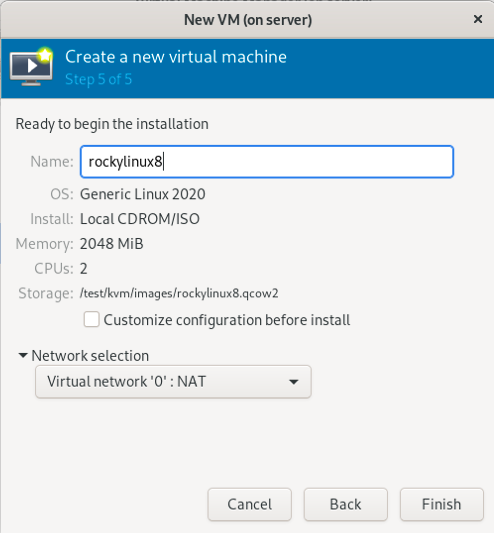
(补充:这里以将虚拟机命名为 rockylinux8 并使用 0 网络为例)
3.2.6 开始安装系统
(只在真机上执行以下步骤)
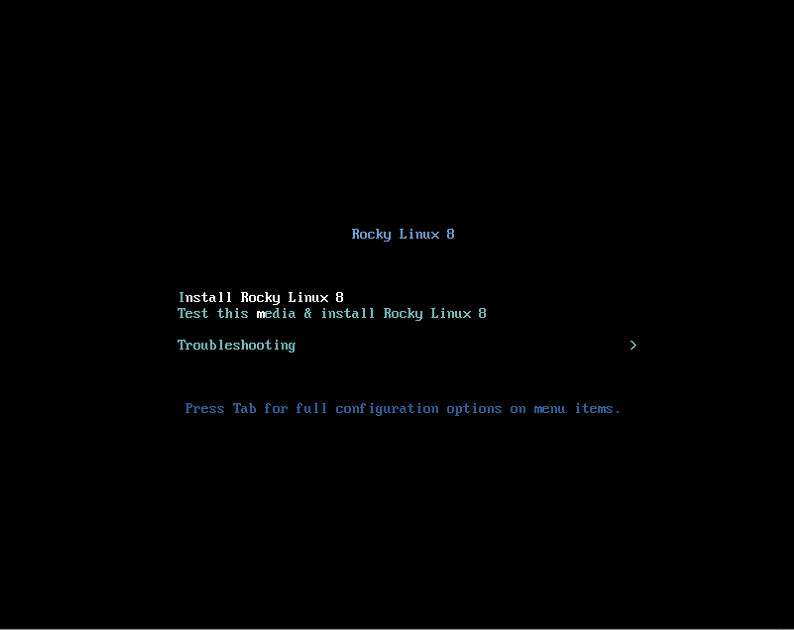
3.2.7 选择系统语言
(只在真机上执行以下步骤)
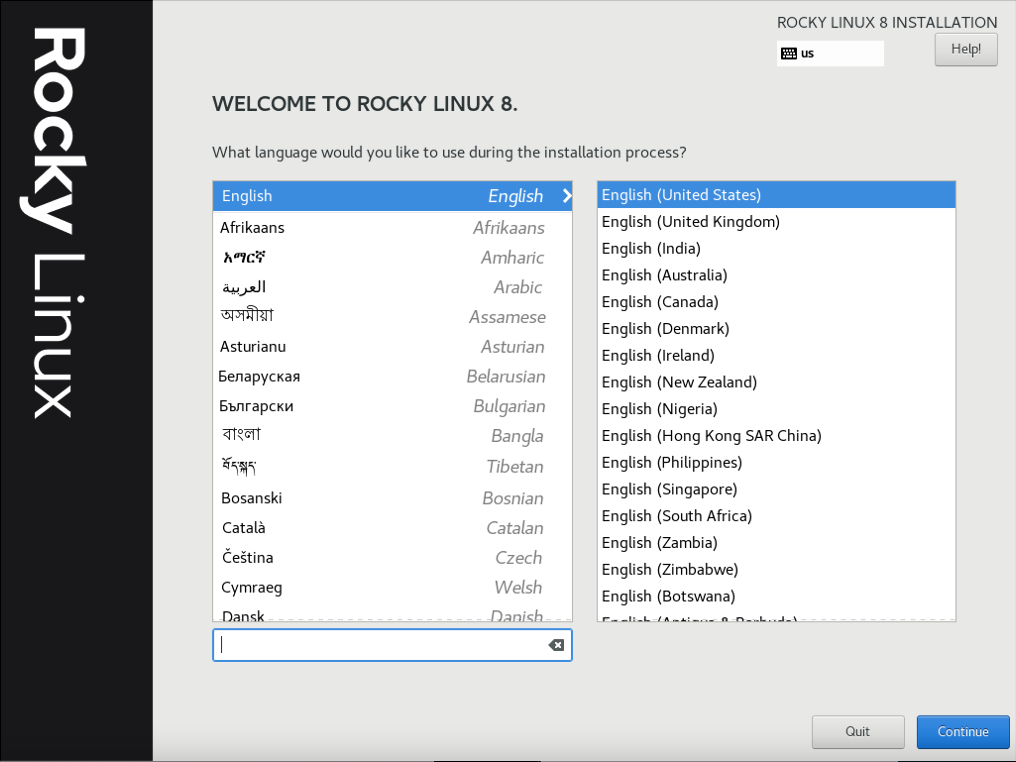
3.2.8 之后进行系统配置界面
(只在真机上执行以下步骤)
需要手动配置的地方有四个:
1) “INSTALLATION DESTINATION”
2) “KDUMP”
3) “SOFTWARE SELECTION”
4) “Root Password”
分别点击以后就可以配置了
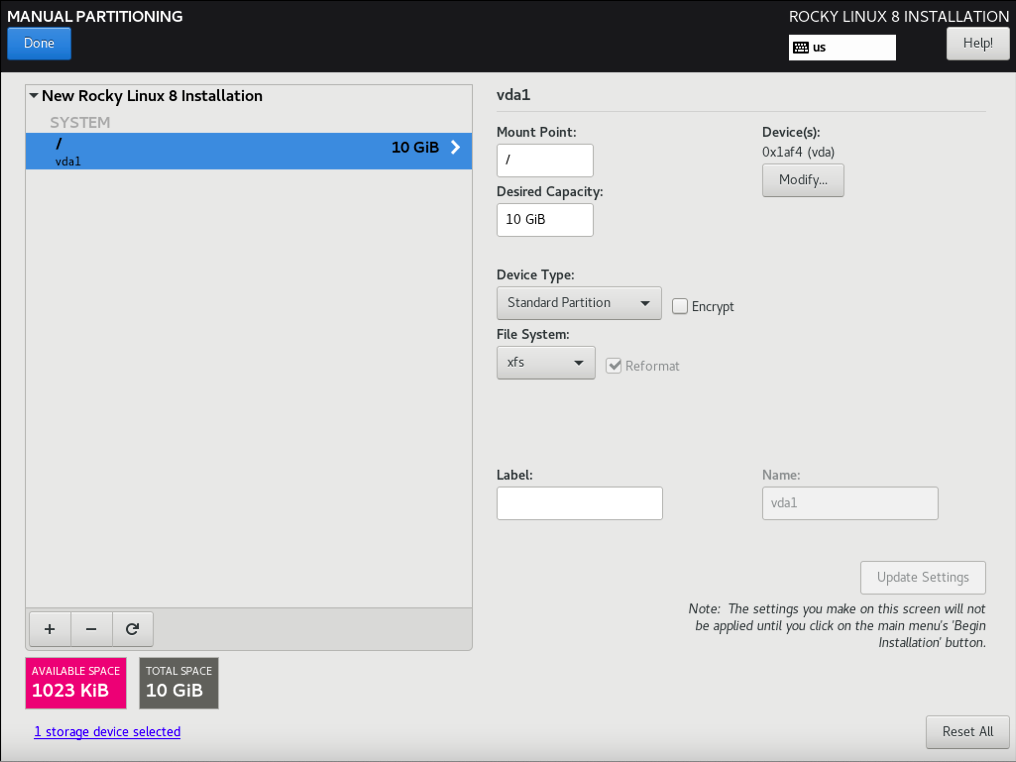
3.2.8.1 通过 “INSTALLATION DESTINATION” 对硬盘进行分区
(只在真机上执行以下步骤)
(补充:完成后点击左上角的 “DONE”)
(注意:只分一个分区,只设置一个挂载点挂载到根,使用标准硬盘类型,硬盘格式设置为 XFS)
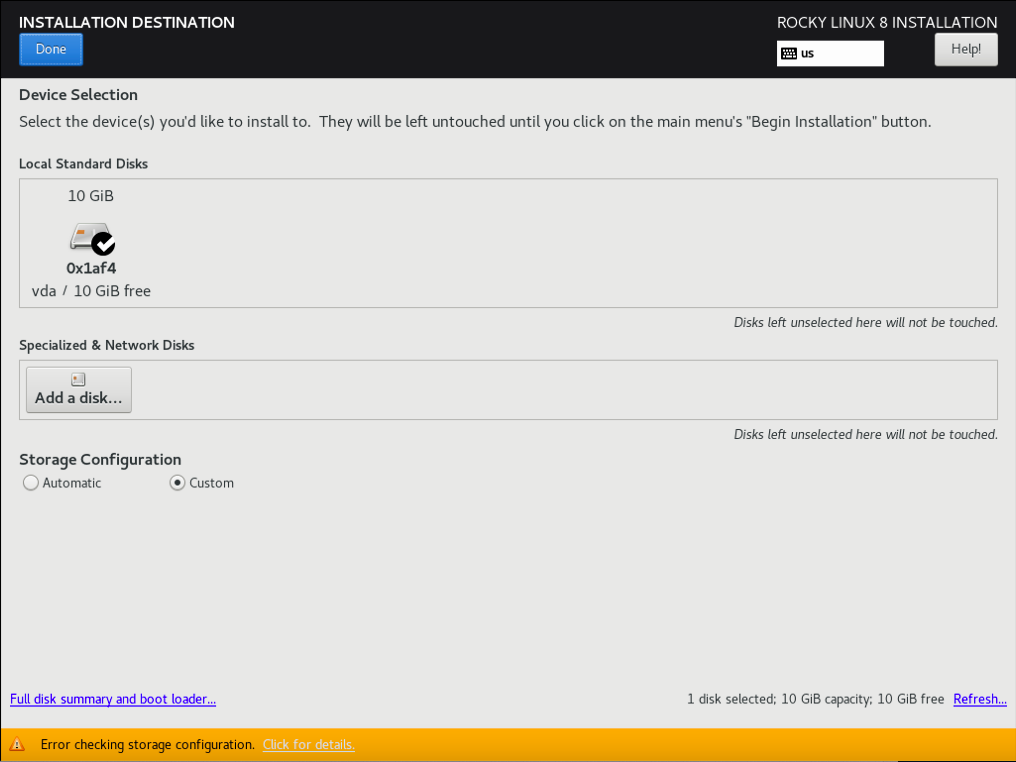
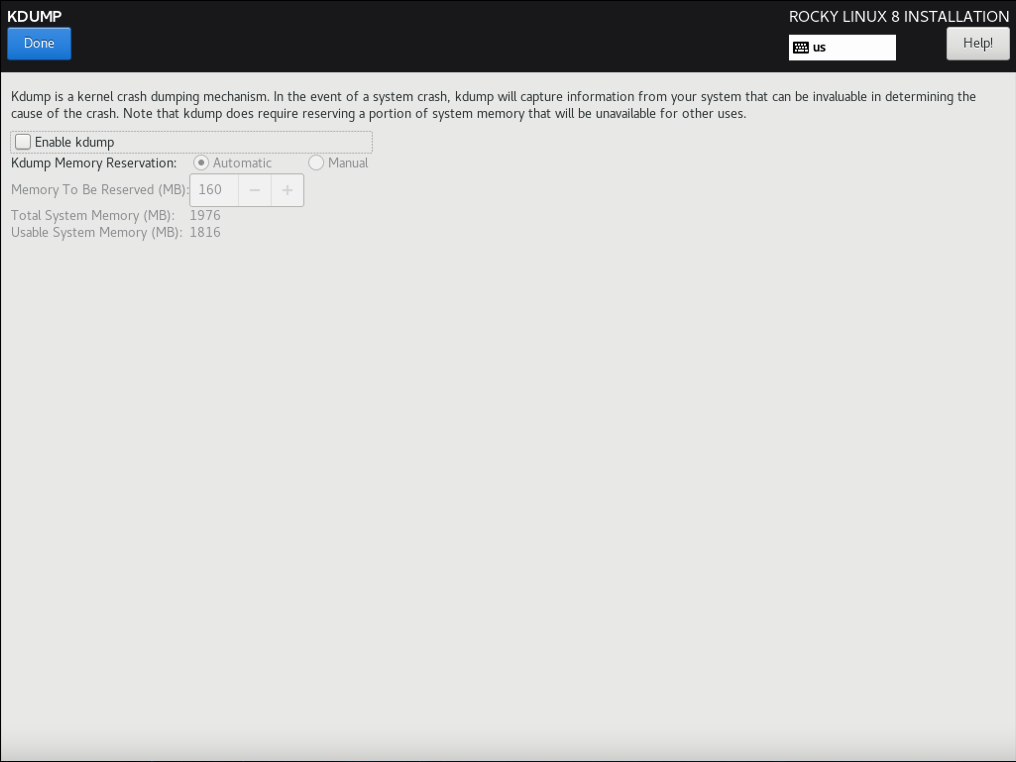
3.2.8.2 取消 “KDUMP”
(只在真机上执行以下步骤)
(补充:完成后点击左上角的 “DONE”)
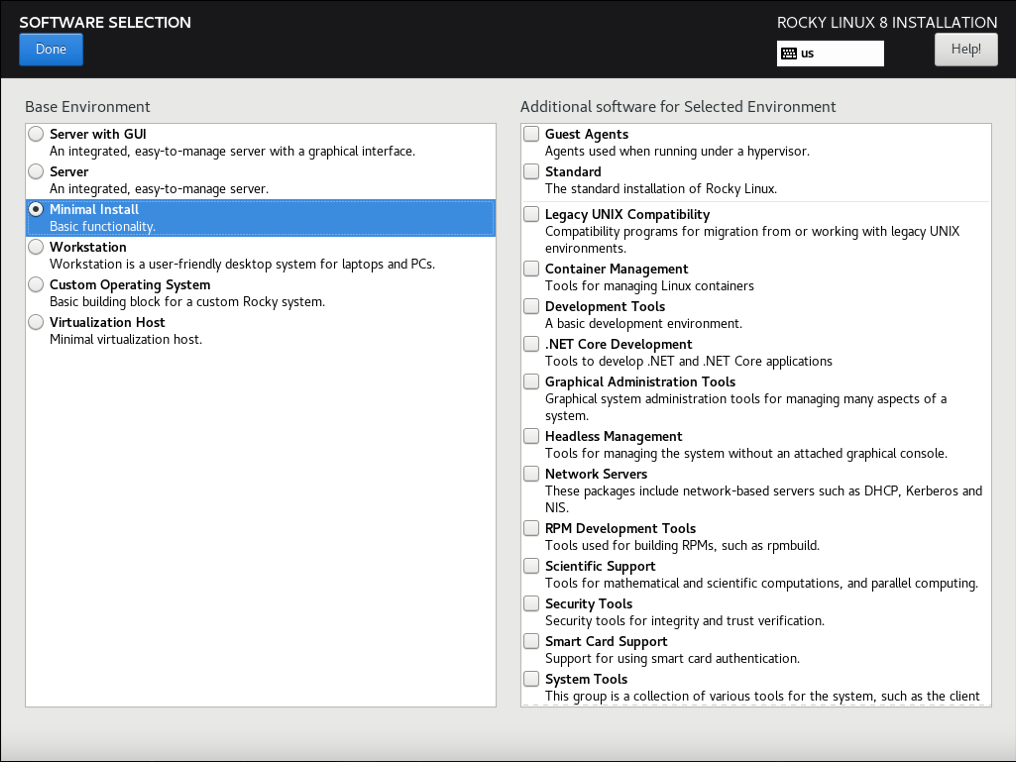
3.2.8.3 选择最小化安装系统
(只在真机上执行以下步骤)
(补充:完成后点击左上角的 “DONE”)
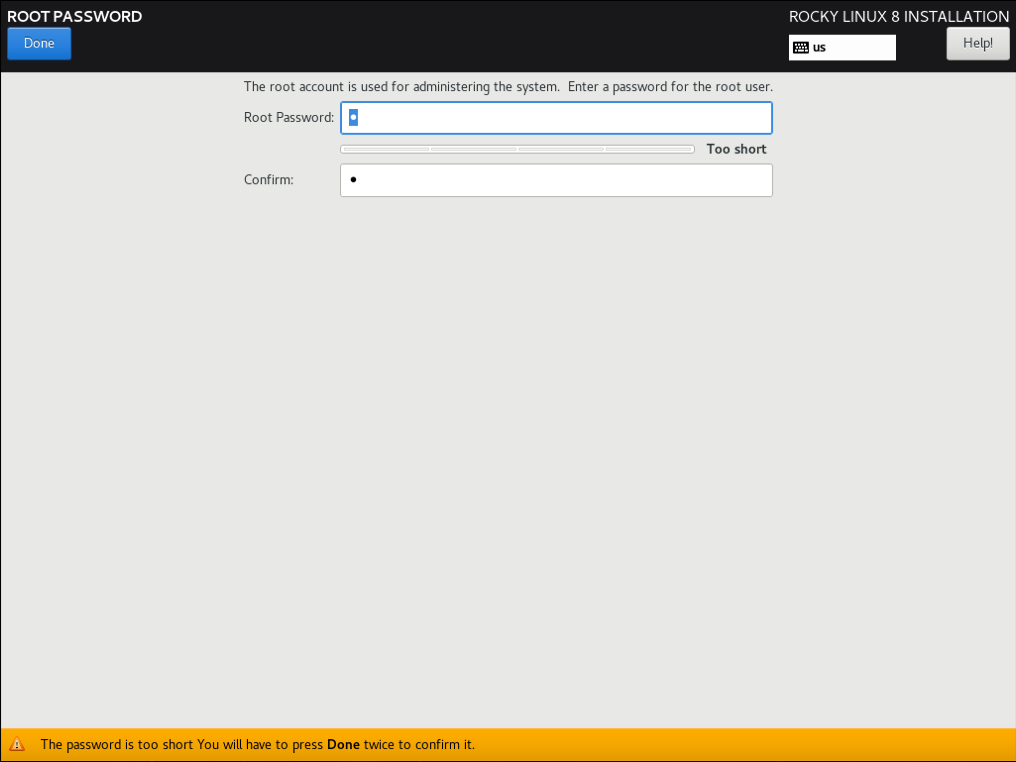
3.2.8.4 设置 root 密码
(只在真机上执行以下步骤)
3.2.9 之后点击右下角的 “Begin installation”
(只在真机上执行以下步骤)
3.2.10 安装完成后重启
(只在真机上执行以下步骤)
3.2.11 在安装系统的过程中需要注意的内容总结
(只在真机上执行以下步骤)
1) 一定要使用刚刚创建的 /var/lib/libvirt/images/rockylinux8.qcow2 作为安装虚拟机的硬件文件
2) 虚拟机网络 “0” 要提前创建好
3) 只分一个分区,只设置一个挂载点挂载到根,使用标准硬盘,硬盘格式是 XFS
4) 取消 “KDUMP”
5) 选择最小化安装系统
6) 设置 root 密码
步骤四:进入新创建虚拟机修改配置
4.1 修改网卡个性化设置
4.1.1 修改网卡配置文件
(只在虚拟机上执行以下步骤)
# vi /etc/sysconfig/network-scripts/ifcfg-enp1s0将全部内容修改如下:
TYPE=Ethernet
BOOTPROTO=dhcp
NAME=enp1s0
DEVICE=enp1s0
ONBOOT=yes4.1.2 使修改的网卡配置生效
(只在虚拟机上执行以下步骤)
# reboot4.2 禁用 SELinux
(只在虚拟机上执行以下步骤)
# vi /etc/selinux/config将全部内容修改如下:
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
SELINUX=disabled
# SELINUXTYPE= can take one of three values:
# targeted - Targeted processes are protected,
# minimum - Modification of targeted policy. Only selected processes are protected.
# mls - Multi Level Security protection.
SELINUXTYPE=targeted4.3 禁用空路由
(只在虚拟机上执行以下步骤)
# vi /etc/sysconfig/network将全部内容修改如下:
# Created by anaconda
NOZEROCONF="yes"4.4 添加 Console 配置
4.4.1 修改 grub 内核配置文件
(只在虚拟机上执行以下步骤)
# vi /etc/default/grub将全部内容修改如下:
GRUB_TIMEOUT=5
GRUB_DISTRIBUTOR="$(sed 's, release .*$,,g' /etc/system-release)"
GRUB_DEFAULT=saved
GRUB_DISABLE_SUBMENU=true
GRUB_TERMINAL="serial console"
GRUB_SERIAL_COMMAND="serial --unit=1 --speed=115200"
GRUB_CMDLINE_LINUX="biosdevname=0 net.ifnames=0 console=tty0 console=ttyS0,115200n8"
GRUB_DISABLE_LINUX_UUID="true"
GRUB_ENABLE_LINUX_LABEL="true"
GRUB_DISABLE_RECOVERY="true"4.4.2 使修改的 grub 内核配置生效
(只在虚拟机上执行以下步骤)
# grub2-mkconfig -o grub4.5 将系统自动挂载的硬盘从使用 UUID 换成硬件路径
4.5.1 显示根分区的 UUID
(只在虚拟机上执行以下步骤)
# blkid
/dev/sda1: UUID="e76ed189-6d0f-49d5-8586-c5aae4bdc9b5" TYPE="xfs" PARTUUID="3d8377ef-01"(补充:这里的 UUID 是: e76ed189-6d0f-49d5-8586-c5aae4bdc9b5)
4.5.2 在自动挂载文件里将根分区的 UUID 换成硬件路径
(只在虚拟机上执行以下步骤)
# vi /etc/fstab将以下内容:
......
UUID=e76ed189-6d0f-49d5-8586-c5aae4bdc9b5 / xfs defaults 0 0(补充:这里的 UUID 是: e76ed189-6d0f-49d5-8586-c5aae4bdc9b5)
修改为:
/dev/sda1 / xfs defaults 0 04.6 删除不用的程序
(只在虚拟机上执行以下步骤)
# yum -y remove firewalld-* python-firewall4.7 对虚拟系统进行升级
(只在虚拟机上执行以下步骤)
# yum -y update4.8 进行分区扩展
4.8.1 安装分区扩展软件
(只在虚拟机上执行以下步骤)
# yum install -y cloud-utils-growpart4.8.2 给开机自启配置文件相应的权限
# chmod 755 /etc/rc.local4.8.3 设置开机自动扩容根目录
(只在虚拟机上执行以下步骤)
# vi /etc/rc.local添加以下内容:
......
/usr/bin/growpart /dev/sda1
/usr/sbin/xfs_growfs /4.9 修改虚拟机系统的名称
(只在虚拟机上执行以下步骤)
# vi /etc/hostname将全部内容修改如下:
rockylinux84.10 启用 serial 服务实现通过 virsh console 命令控制虚拟机
(只在虚拟机上执行以下步骤)
# systemctl start serial-getty@ttyS0
# systemctl enable serial-getty@ttyS04.11 清除虚拟系统的历史命令
(只在虚拟机上执行以下步骤)
# history -c4.12 关闭虚拟机
(只在虚拟机上执行以下步骤)
# poweroff步骤五:在真机上对虚拟机进行清理优化
(只在真机上执行以下步骤)
# sudo virt-sysprep -d rockylinux8(补充:这里以清理 rockylinux8 虚拟机为例)
(
注意:如果此命令不存在
1) Rocky Linux 系统的话需要安装 libguestfs-tools
2) openSUSE 系统的话需要安装 guestfs-tools
)
步骤六:此时就可以将此虚拟机的硬件文件作为模板进行批量克隆虚拟机了
(只在真机上执行以下步骤)